
Introduction to sklearn dta set timeseries
In the fast-paced world of data science, time is money. As we dive deeper into machine learning, the ability to analyze and interpret time series data has become paramount. The sklearn dta set timeseries is a treasure trove for those looking to harness the power of temporal information in their models. Whether you’re predicting stock prices or forecasting weather patterns, understanding how to manipulate this dataset can be a game changer.
But why should you care? Because transforming your ML models with accurate time series analysis can lead to more precise predictions and better decision-making. Join us as we explore the ins and outs of sklearn dta set timeseries, uncovering techniques that will elevate your machine learning projects from good to great. Let’s embark on this journey together!
ALSO READ: teoria da modelagem estatística: From the Model to Prediction
The Importance of Transforming ML Models
Transforming machine learning models is crucial for ensuring their effectiveness. Raw data often contains noise and irrelevant features, which can hinder model performance. By transforming the data, we improve its quality and relevance.
Effective transformations can also enhance interpretability. When features are well-defined and clear, it becomes easier to understand how a model makes decisions. This transparency builds trust among users.
Moreover, certain algorithms require specific input formats or scales to function optimally. Transformations like normalization or standardization help meet these requirements.
In the realm of time series data, transformations enable better trend detection and forecasting accuracy. They allow models to adapt quickly to changes in patterns over time.
Investing effort into transforming ML models pays dividends in both accuracy and usability. The right transformation sets the stage for robust analysis and powerful predictions across various applications.
Techniques for Transforming sklearn dta set timeseries
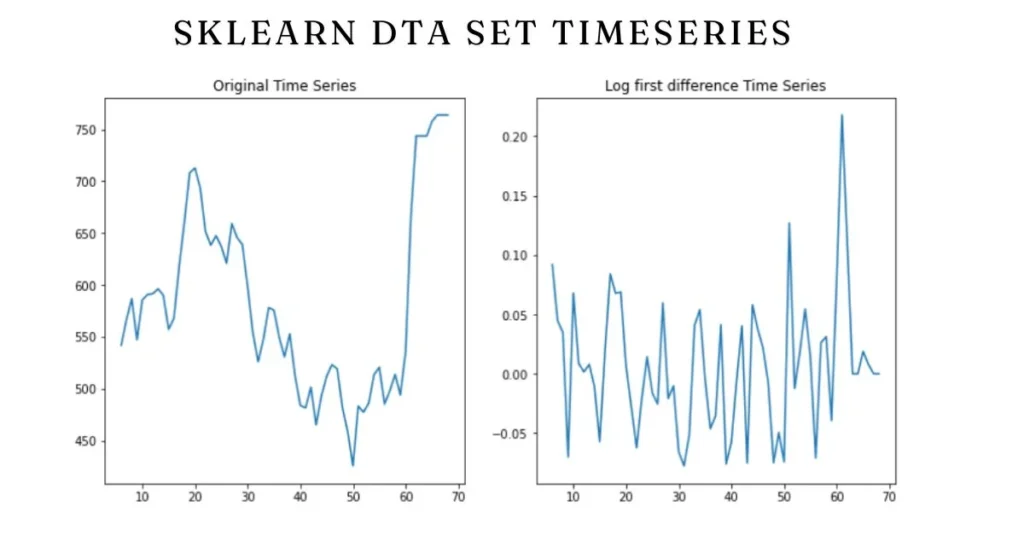
Transforming sklearn dta set timeseries involves several techniques that enhance model performance. A common approach is resampling, which allows you to adjust the frequency of your time series data. This can help in analyzing trends over different time intervals.
Another valuable technique is differencing. By subtracting the previous observation from the current one, you can remove non-stationarity from your dataset. This step often stabilizes the mean and variance across time.
Feature engineering also plays a crucial role. Creating lagged features or rolling averages provides models with more context about previous values, enriching their predictive capabilities.
Normalization and scaling are equally important when dealing with timeseries data. These processes ensure that all input features contribute equally to distance calculations during training.
Employing seasonal decomposition helps identify underlying patterns within your data by breaking it down into trend, seasonality, and residual components. Each technique contributes uniquely to transforming your sklearn dta set timeseries for optimal results in machine learning models.
Implementing Sklearn on Time Series Data
Implementing Sklearn on time series data can be a game changer for predictive analytics. The library offers robust tools tailored for handling sequences and trends over time.
Start by preprocessing your dataset. Ensure that your timestamps are in the correct format. This step is crucial because most algorithms assume numerical inputs.
Next, split your data into training and testing sets while preserving the temporal order. Unlike random splits, this method maintains the sequence essential for effective learning.
Feature engineering plays a vital role as well. Create lag features or rolling statistics to help models capture patterns over time. Don’t forget about scaling; standardizing or normalizing features can enhance model performance significantly.
Choose an appropriate algorithm from Sklearn—be it linear regression or decision trees—and fit it to your transformed dataset. With careful implementation, you can unlock valuable insights from time series analysis using Sklearn’s powerful capabilities.
Case Study: Predicting Stock Prices with Sklearn and Time Series Data
Predicting stock prices is a fascinating challenge that showcases the power of machine learning. Using the sklearn dta set timeseries, analysts can uncover patterns in historical data to forecast future movements.
Consider using a combination of moving averages and exponential smoothing techniques as features. These methods help capture trends and seasonality effectively. The goal is to train models that adapt quickly to new information while minimizing lag.
A popular choice for this task is the Random Forest algorithm due to its robustness against overfitting. By evaluating multiple time-series predictors, one can achieve impressive accuracy levels.
Visualizing predictions alongside actual price movements brings insights into model performance. This step not only highlights strengths but also reveals areas needing improvement.
The interplay between finance and machine learning continues to grow, making such case studies vital for those looking to innovate in predictive analytics within financial markets.
Other Applications of Sklearn and Time Series Data
Sklearn’s capabilities extend far beyond stock price predictions. Its versatility makes it a great choice for various time series applications.
One area is weather forecasting. By analyzing historical climate data, models can predict future temperature patterns and precipitation levels accurately. This helps in planning agricultural activities and disaster management.
Another exciting application lies in energy consumption forecasting. Utilities can analyze past usage to anticipate demand peaks, optimizing resource allocation accordingly.
Healthcare also benefits from time series analysis using sklearn. Monitoring patient vitals over time allows for early detection of anomalies, improving patient outcomes significantly.
Even retail sectors utilize these techniques to forecast sales trends based on seasonal fluctuations or promotional impacts, ensuring they have the right inventory at the right times.
With its robust functionality, sklearn continues to unlock new possibilities across different fields when applied to time series data.
Conclusion of sklearn dta set timeseries
The world of machine learning is constantly evolving, and the sklearn dta set timeseries offers a unique opportunity for practitioners to harness the power of time-based data. Transforming ML models tailored for such datasets can lead to significant improvements in accuracy and predictive capability.
As we’ve explored, transforming your approach when dealing with time series can unlock new insights and drive better decision-making. Whether predicting stock prices, analyzing weather patterns, or optimizing supply chains, understanding how to work with time-sequenced data is crucial.
Techniques like differencing, windowing, and lag feature creation are just a few that empower data scientists to make more informed predictions. With tools from sklearn at your disposal, implementing these transformations becomes an accessible task for anyone looking to dive into the realm of time series analysis.
As you continue exploring this fascinating field, remember that each dataset tells its own story through its temporal characteristics. Embracing the intricacies of sklearn dta set timeseries will not only enhance your models but also broaden your analytical horizons in machine learning applications across various industries.
ALSO READ: Lessons from the Art Room: Teaching, Learning, and Creativity
FAQs
What is “sklearn dta set timeseries”?
Sklearn dta set timeseries refers to datasets used in machine learning that incorporate time-based data for predictions and analysis, enabling models to handle sequences and trends over time.
How do you transform sklearn dta set timeseries for machine learning?
Transforming time series data includes techniques like resampling, differencing, feature engineering (e.g., lag features), normalization, and seasonal decomposition to improve model accuracy.
Why is transforming time series data important for machine learning models?
Transforming time series data helps remove noise, stabilize trends, and ensure that models can effectively capture temporal patterns for more accurate predictions.
Which sklearn models are best for time series forecasting?
Models like Random Forest, Linear Regression, and XGBoost work well for time series forecasting when combined with proper feature engineering and data transformations.
How does sklearn handle time series data in forecasting?
Sklearn allows for preprocessing time series data, creating lag features, splitting data with temporal order, and using models like Random Forest for effective forecasting tasks.





