
Introduction to data pipeline journey
In today’s data-driven world, businesses are generating massive amounts of raw data every second. Yet, this wealth of information is only as valuable as the insights we can extract from it. Enter the data pipeline journey—a structured approach to transforming unrefined data into actionable intelligence. This journey not only streamlines processes but also empowers organizations to make informed decisions that drive growth and innovation.
As companies navigate through a sea of information, understanding how to harness the potential hidden within their data has become crucial. Whether you’re a startup or an established enterprise, mastering your own data pipeline journey can set you apart from competitors and unlock new opportunities for success. Let’s dive deep into what this journey entails and discover how it can lead your business toward greater value creation.
ALSO READ: Solving Jacksonville Computer Network Issue: A Quick Guide
The Importance of data pipeline journey in Business
The data pipeline journey is crucial for modern businesses. It transforms raw data into actionable insights, guiding decision-making processes.
In a world driven by information, companies rely on accurate and timely data. A well-structured data pipeline ensures that this information flows seamlessly from collection to analysis.
Moreover, it enhances efficiency. Automating various stages of the pipeline minimizes manual errors and saves time. This allows teams to focus on strategic initiatives rather than getting bogged down in mundane tasks.
Additionally, the competitive edge gained through effective data utilization cannot be overlooked. Businesses can identify trends faster and respond proactively to market changes.
An optimized data pipeline turns complexity into clarity, enabling organizations to harness their full potential.
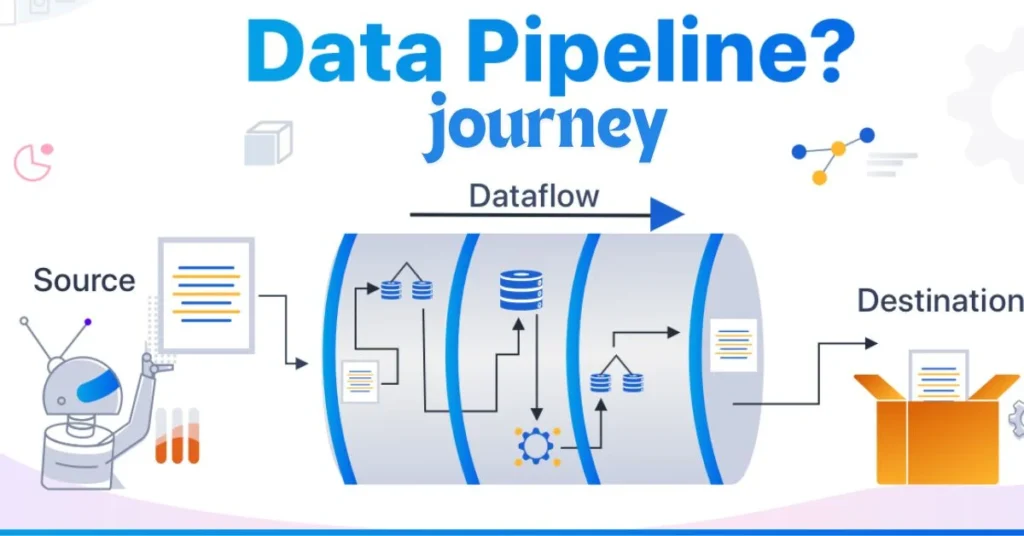
Stages of a data pipeline journey
The data pipeline journey unfolds in several key stages, each crucial for transforming raw information into actionable insights.
First, there’s data collection. This involves gathering information from diverse sources such as databases, APIs, and even social media platforms.
Next comes data ingestion. Here, the collected data enters the pipeline process. This stage ensures that all incoming data is securely transferred for further processing.
Following ingestion is transformation. During this phase, raw data undergoes cleaning and formatting to ensure accuracy and consistency. It’s essential for making sense of massive datasets.
Data storage is another critical step where transformed data is organized within a database or warehouse structure for easy accessibility.
We reach the visualization stage. At this point, stakeholders can analyze trends and derive insights through dashboards or reports tailored to their needs. Each stage plays an integral role in realizing the full potential of a successful data pipeline journey.
Tools and Technology Used in data pipeline journey
In the data pipeline journey, various tools and technologies play crucial roles. ETL (Extract, Transform, Load) tools are foundational. They help in gathering raw data from different sources, transforming it into a usable format, and loading it into storage systems.
Apache Kafka is another notable player. It excels at handling real-time data streams. This capability allows businesses to process information on-the-fly without lag.
Cloud platforms like AWS or Google Cloud offer robust infrastructure for scalability. Organizations can manage vast amounts of data effortlessly using their services.
Data orchestration tools such as Apache Airflow streamline workflows. They automate complex tasks within the pipeline while ensuring everything runs smoothly.
Visualization tools like Tableau or Power BI breathe life into raw numbers. They turn insights into compelling visual stories that drive decision-making across teams.
Common Challenges in Building a Data Pipeline
Building a data pipeline can be a complex endeavor. Many organizations face hurdles that can derail their efforts.
Data integration is often tricky. Organizations may use different sources, formats, and systems. Merging these diverse elements into a cohesive flow presents significant obstacles.
Scalability is another concern. As businesses grow, so does the volume of data they handle. Ensuring that the pipeline can scale without performance issues requires foresight in design.
Data quality cannot be overlooked either. Inconsistent or erroneous data leads to unreliable insights. Regular monitoring and cleansing become essential parts of maintaining accuracy.
Team skills play an important role in success. A lack of expertise in modern tools and technologies may slow down progress or compromise results entirely.
Navigating these challenges demands careful planning and proactive strategies to ensure a smooth journey through the data landscape.
Best Practices for an Effective Data Pipeline
Building an effective data pipeline requires thoughtful design and execution. Start by defining clear objectives. Understand what you need from your data. This clarity will guide every subsequent step.
Next, ensure robust data quality checks throughout the process. Clean and accurate data is essential for reliable insights.
Automate where possible to reduce manual errors and improve efficiency. Automation tools can help streamline repetitive tasks, freeing up valuable time for analysis.
Scalability should also be a priority. Plan for future growth in both volume and complexity of your datasets.
Regularly monitor performance metrics too. Keeping an eye on how well your pipeline operates helps identify potential bottlenecks early.
Foster collaboration among teams involved in the pipeline’s lifecycle. Communication ensures that everyone is aligned with goals and challenges alike, creating a more resilient structure overall.
Case Study: Successful Implementation of a Data Pipeline
A leading e-commerce company faced challenges in managing vast amounts of customer data. They struggled to extract insights quickly, which hindered their marketing strategies and customer engagement.
To tackle this issue, they implemented a robust data pipeline journey. This setup streamlined the flow of data from various sources like web analytics, sales platforms, and social media channels into a centralized database.
Using modern tools like Apache Kafka for real-time processing and Tableau for visualization transformed their analytical capabilities. Their teams gained access to timely insights that drove targeted campaigns.
As a result, they improved conversion rates by 30% within six months. These advancements also enabled personalized recommendations based on user behavior, enhancing overall customer experience significantly. The success story underscores the importance of an effective data pipeline in unlocking actionable insights swiftly.
Future of Data Pipelines: Trends and Predictions
The future of data pipelines is poised for exciting transformations. As organizations generate more data, the demand for agile and scalable solutions will surge.
One notable trend is the increasing adoption of real-time processing. Businesses are leaning towards immediate insights rather than waiting for batch processes. This shift enhances decision-making capabilities.
Automation will play a crucial role as well. Intelligent automation tools can streamline workflows, reducing manual intervention and minimizing errors in data handling.
Cloud technology continues to shape data pipeline architectures too. With cloud services offering flexibility and scalability, many companies are migrating their operations to these platforms for improved performance.
Machine learning integration within pipelines is becoming essential. It not only facilitates predictive analytics but also optimizes every stage from ingestion to transformation, adding significant value throughout the journey.
These trends signal an era where data pipelines become even more integral to business strategies, driving innovation and efficiency across industries.
Conclusion
The data pipeline journey is a vital component of modern business strategies. As organizations grapple with the exponential growth of data, having an efficient pipeline in place can mean the difference between success and stagnation. By understanding each stage, leveraging the right tools, and navigating challenges effectively, businesses can transform raw data into actionable insights.
Adopting best practices ensures that pipelines remain robust and adaptable to changing needs. As we look forward, trends indicate a future where automation and advanced analytics will play critical roles in streamlining these journeys even further.
Embracing this evolution not only enhances decision-making capabilities but also positions companies at the forefront of innovation. The journey from raw data to valuable insights is ongoing—one that every organization should take seriously as they navigate their unique landscapes in today’s digital age.
ALSO READ: /portal.php: Essential Tool for Efficient Web Development
FAQs
What is the “data pipeline journey”?
The data pipeline journey is the process of transforming raw data into actionable insights by moving it through stages like collection, ingestion, transformation, and visualization.
Why is the data pipeline journey important for businesses?
It enables companies to efficiently convert raw data into valuable insights, enhancing decision-making, improving operational efficiency, and gaining a competitive edge.
What are the key stages of a data pipeline journey?
The key stages include data collection, ingestion, transformation, storage, and visualization, each vital in preparing data for analysis and decision-making.
What tools are commonly used in a data pipeline journey?
Tools like ETL software, Apache Kafka, cloud platforms (AWS, Google Cloud), and visualization tools like Tableau or Power BI are frequently used to manage and process data pipelines.
How can businesses overcome challenges in building a data pipeline?
By focusing on data integration, scalability, quality control, and using automation, businesses can streamline their pipelines and ensure efficient, error-free data processing.





