
Introduction to Pyspark spark.default.parallelism
Welcome to the world of PySpark, where big data meets powerful analytics. If you’re delving into this realm, understanding how to harness parallel processing is key. One crucial aspect that often gets overlooked is the pyspark spark.default.parallelism configuration. This setting plays a vital role in determining how your Spark jobs perform and scale across multiple nodes.
Whether you’re a seasoned developer or just starting out with PySpark, mastering this configuration can lead to significant improvements in job execution speed and resource utilization. So, let’s dive deeper into what spark.default.parallelism really means and why it deserves your attention!
ALSO READ: Data Pipeline Journey: Transforming Raw Data Into Value
Understanding the spark.default.parallelism Configuration
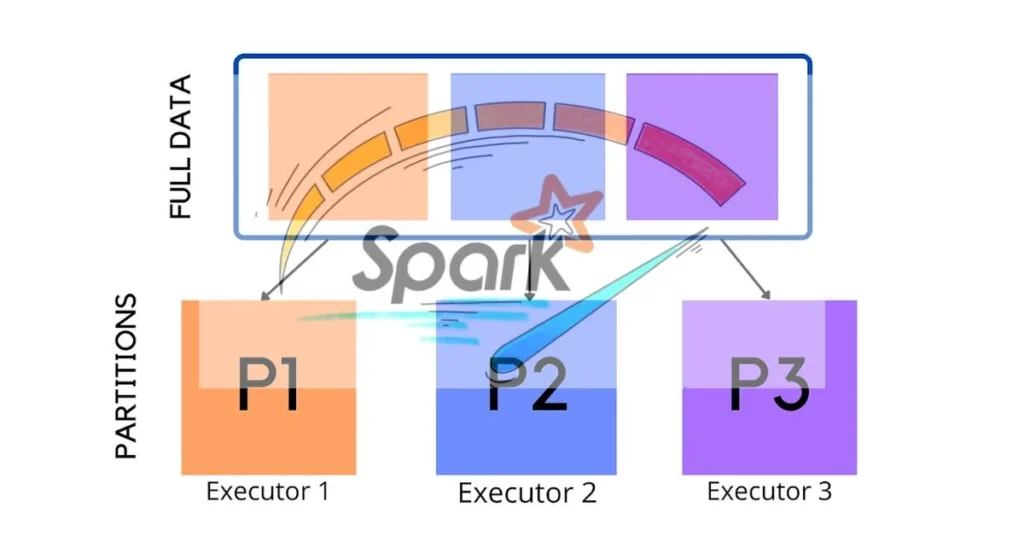
The `spark.default.parallelism` configuration is crucial in PySpark. It determines the number of partitions that will be used when processing data in various operations, such as transformations and actions.
By default, this value is set based on your cluster’s resources. Typically, it equals the total number of cores across all active nodes. However, adjusting this parameter can significantly influence job performance and resource utilization.
When working with large datasets or complex computations, optimal parallelism becomes essential. If set too low, tasks may run slowly due to insufficient parallel execution. Conversely, an excessively high setting can lead to overhead from managing numerous small tasks.
Understanding how to fine-tune this configuration can enhance efficiency and reduce runtime dramatically. Analyzing workload characteristics will help you decide the best approach for your specific needs.
Benefits of Configuring spark.default.parallelism
Configuring `spark.default.parallelism` can significantly enhance the performance of your PySpark applications. By optimizing parallelism, you allow Spark to distribute tasks more efficiently across available cores in your cluster.
This leads to faster data processing times. With increased parallelization, jobs can run simultaneously rather than sequentially, reducing wait times for results.
Another benefit is improved resource utilization. When configured correctly, it helps ensure that all compute resources are actively engaged without overwhelming any single node. This balance prevents bottlenecks and enhances overall system throughput.
Moreover, adjusting this setting allows for better handling of large datasets. It ensures that partitions are appropriately sized and distributed, which minimizes shuffle operations that can slow down execution.
Fine-tuning `spark.default.parallelism` contributes to a smoother workflow and greater scalability as your data processing needs evolve over time.
Factors to Consider When Setting spark.default.parallelism
When setting the `spark.default.parallelism` configuration, several factors come into play. One crucial aspect is the cluster size. The number of available cores directly influences how you can distribute tasks across nodes.
Next, consider your data’s characteristics. Large datasets often require higher parallelism to enhance performance and reduce processing time. Conversely, for smaller datasets, excessive parallelism may lead to overhead without significant gains.
Workload type also matters. Batch jobs typically benefit from different settings compared to streaming applications. Understanding your workload allows for better tuning of this parameter.
Monitor resource utilization metrics during execution. These insights help refine the configuration over time for optimal results in varied scenarios while maintaining efficiency throughout the process.
How to Configure spark.default.parallelism in Pyspark
Configuring `spark.default.parallelism` in PySpark is straightforward and can significantly enhance your application’s performance.
To set this parameter, you typically define it within the SparkConf object while initializing your Spark session. This can be done with a simple line of code.
“`python
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName(“YourAppName”) \
.config(“spark.default.parallelism”, “number_of_partitions”) \
.getOrCreate()
“`
Replace `”number_of_partitions”` with the desired level of parallelism based on your cluster configuration or workload needs.
Another approach involves adjusting the value through command-line options when launching a PySpark application. Use `–conf` followed by the key-value pair for customization.
Experimenting with these settings will help find an optimal balance for various tasks, ensuring efficient resource utilization across clusters.
Case Studies: Real-world Examples of Using spark.default.parallelism
A leading e-commerce platform faced performance challenges during peak sales periods. By adjusting the pyspark spark.default.parallelism setting, they optimized their data processing. This tweak allowed them to handle larger datasets efficiently, resulting in faster transaction times.
In another case, a financial analytics firm processed real-time stock market data using PySpark. They found that increasing parallelism reduced latency significantly during high-volume trading hours. As a result, they could deliver insights more rapidly to clients and improve decision-making processes.
A telecommunications company also reaped benefits from configuring spark.default.parallelism. By aligning it with their cluster size and workload type, they achieved better resource utilization. This led to enhanced operational efficiency and lower costs while managing large volumes of customer data for analytics purposes.
Conclusion
Configuring the spark.default.parallelism in Pyspark is a crucial step for optimizing your data processing tasks. Understanding its significance and effectively adjusting this parameter can lead to improved performance and resource management.
The ability to manage parallelism allows developers to harness the full power of their cluster, ensuring that jobs run efficiently. By considering various factors such as cluster size and workload characteristics, you can make informed decisions about setting this configuration.
Real-world examples demonstrate how organizations have successfully implemented these insights, resulting in faster job execution times and better resource utilization. As you continue your journey with Pyspark, keep an eye on the spark.default.parallelism settings—it might just be the key to unlocking enhanced performance for your big data applications.
ALSO READ: Solving Jacksonville Computer Network Issue: A Quick Guide
FAQs
What is “pyspark spark.default.parallelism”?
pyspark spark.default.parallelism is a configuration parameter in PySpark that defines the default number of partitions in RDDs during transformations like join, reduceByKey, and parallelize. It determines how tasks are distributed across available cores in the cluster.
Why is spark.default.parallelism important for PySpark jobs?
It plays a crucial role in determining the level of parallelism during job execution. Proper configuration helps optimize resource utilization, improve processing speed, and avoid unnecessary overhead, making your PySpark applications more efficient.
How do I configure spark.default.parallelism in PySpark?
You can configure spark.default.parallelism by setting it in the SparkConf object when initializing a Spark session. Example:pythonCopyspark = SparkSession.builder \ .config("spark.default.parallelism", "desired_number_of_partitions") \ .getOrCreate()
What factors should I consider when setting spark.default.parallelism?
Key factors include cluster size, data volume, workload type (batch vs. streaming), and resource utilization. Adjusting for these variables ensures that tasks are distributed efficiently across the cluster.
Can spark.default.parallelism impact job performance?
Yes, improper configuration of spark.default.parallelism can result in slow task execution or resource imbalance. Fine-tuning this setting allows better resource utilization and faster job completion, especially for large datasets or complex computations.





